The Retrieval Bottleneck You Didn't Know You Had
If you've been building Retrieval-Augmented Generation (RAG) systems for more than a week, you've likely hit that frustrating wall where your LLM hallucinating because the retriever served up a perfectly relevant-looking snippet that was, in fact, missing the most critical piece of information. You check the vector database, find the chunk, and realize the problem: the snippet says "It was founded in 1994," but the word 'Amazon' was five sentences back in the previous chunk. To your embedding model, that 'it' is a ghost. Your late chunking RAG strategy—or lack thereof—is effectively lobotomizing your data before it even hits the index.
We’ve been conditioned to accept 'Split -> Embed -> Store' as the holy trinity of RAG architecture. We obsess over chunk sizes, overlaps, and recursive character splitters, but we rarely talk about the fundamental flaw: traditional chunking treats your document like a pile of isolated islands. When you split a document before embedding it, you lose the global semantic field. You’re asking the model to understand a paragraph without letting it read the rest of the chapter. It's time to flip the script.
The 'Broken Reference' Problem in Semantic Retrieval
In standard pipelines, once a text is sliced into 300-token blocks, each block is fed into an embedding model independently. This creates a massive issue with anaphora—words like 'he', 'she', 'it', or 'the company' that refer back to an entity established earlier. In a practical implementation study, researchers found that similarity scores for these context-dependent chunks often hover around 70%, but jump significantly when the model is allowed to 'see' the surrounding text. When a chunk is isolated, its vector representation is weak because the embedding model is guessing the subject. This vector search context loss is the silent killer of RAG precision.
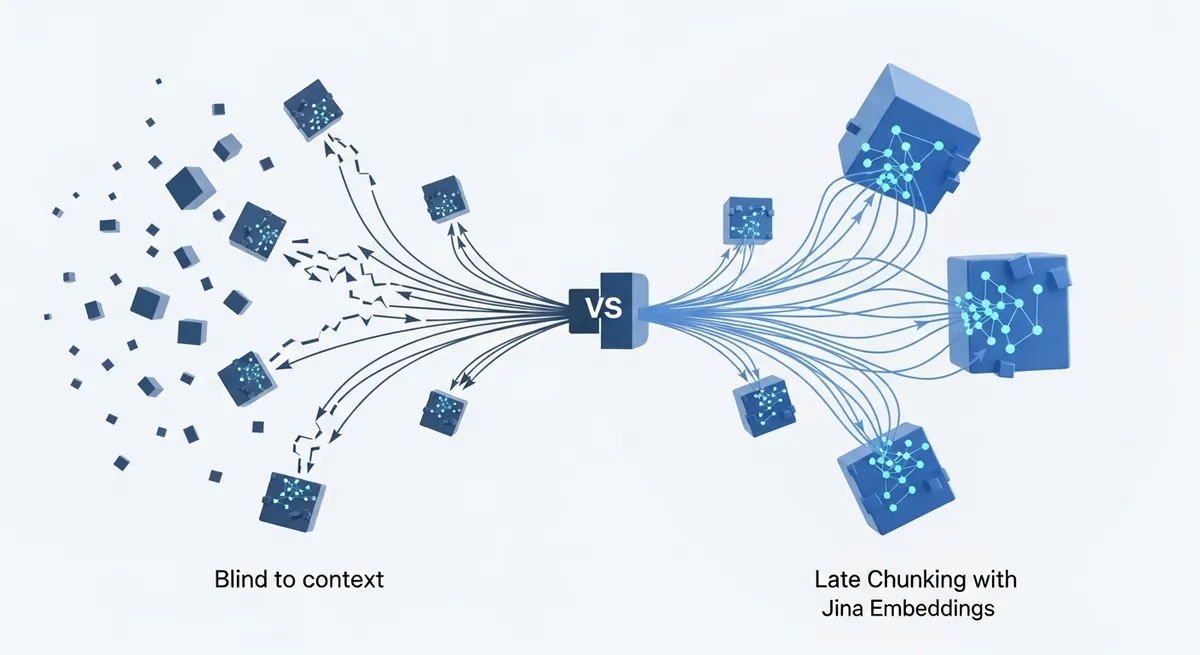
What is Late Chunking?
Late chunking is a clever architectural shift popularized by the team at Jina AI. Instead of splitting text first, you feed the entire document (or a large window of it) into a long-context model like Jina Embeddings v3. But here's the trick: instead of taking the final pooled embedding for the whole document, you extract the token-level embeddings first.
The workflow looks like this:
- Embed: Pass the full document through the transformer. Because modern models use self-attention, every token 'attends' to every other token. The 'it' in paragraph five now physically contains the mathematical influence of the subject defined in paragraph one.
- Chunk: Define your boundary points on the document as you normally would.
- Pool: Perform mean pooling on the token embeddings within those boundaries to create your chunk vectors.
By delaying the pooling step, each chunk inherits the global context of the entire document. You get the granularity of a small chunk with the 'intelligence' of the full text.
Why Jina Embeddings v3 Changes the Game
This isn't just theoretical. The research paper "Late Chunking: Contextual Chunk Embeddings Using Long-Context Embedding Models" demonstrates that this approach can boost retrieval accuracy by approximately 6.5 nDCG@10 points. That is a massive leap in a field where we usually fight for fractions of a percent.
The Power of the 8k Window
Traditional BERT-based models had a 512-token limit. If you tried late chunking there, you’d run out of room before you finished the introduction. Jina Embeddings v3 supports an 8192-token context window. That’s roughly 10-15 pages of text. This allows the model to maintain semantic retrieval optimization across massive technical manuals or legal contracts in a single forward pass.
Computational Efficiency
You might think embedding a whole document at once is slower. Actually, it’s often the opposite. In a naive pipeline, if you have overlapping chunks, you are redundantally processing the same tokens multiple times. Late chunking requires exactly one forward pass through the transformer. It is computationally leaner and eliminates the redundant math, though it does require more VRAM to hold those token-level embeddings before they are pooled into final vectors.
Late Chunking vs. Contextual Retrieval
There has been a lot of buzz around Anthropic’s 'Contextual Retrieval,' where an LLM prepends a short summary of the document to every single chunk. While effective, it is brutally expensive. You’re paying for LLM tokens for every chunk in your database. Late chunking RAG provides a 'free' version of this. You get the context through the transformer's own attention mechanism without needing an expensive generation step. It’s a structural solution rather than a brute-force one.
Implementation Reality Check
Before you go all-in, there are two things you need to know. First, this is model-agnostic but requires access to the hidden states of the model. This means you can't easily do this with closed-source APIs like OpenAI or Cohere yet, as they only return the final pooled vector. You need models where you can control the pooling layer, like Jina or Nomic. Second, you are still capped by the model's max sequence length. If your document is a 500-page book, you'll still need to split it into 8k-token segments first, then apply late chunking within those segments.
Moving Toward Context-Aware AI
The transition from naive chunking to late chunking represents a shift in how we view data. We are moving away from treating text as a bag of strings and toward treating it as a coherent web of meaning. If you are still seeing 'near misses' in your RAG performance—where the right document is found but the wrong part is prioritized—late chunking is the most logical next step for your stack.
Ready to try it? You can implement this today using Jina’s open-source weights or their API, which now supports late chunking natively. Stop letting your chunks live in isolation; give them the context they deserve.

