The 3 AM Alert Nobody Wants
Imagine this: You've finally perfected your auto-scaling groups. A traffic spike hits, your HPA triggers, and 500 new nodes spin up to meet the demand. But instead of a seamless scale-out, your dashboards turn blood-red. Your container registry—whether it's ECR, GCR, or a self-hosted instance—is choking. Pull-through latencies skyrocket, 503 errors flood the logs, and your 'high availability' system is paralyzed by a thundering herd of nodes all begging for the same 5GB image layer at the exact same millisecond. Your centralized registry isn't just a storage bucket; it's a massive Single Point of Failure (SPOF) waiting to snap under pressure.
If you're managing large-scale Kubernetes clusters or, increasingly, distributing 100GB+ LLM weights for GenAI workloads, the traditional 'pull-from-source' model is functionally obsolete. This is where Dragonfly P2P image distribution changes the game. Recently graduated to the CNCF's highest maturity level, Dragonfly turns every node in your cluster into a contributor rather than just a consumer.
The Math of Failure: Why Centralized Registries Don't Scale
In a standard environment, if you deploy a 70B parameter AI model (~130GB) to 200 nodes, your registry must serve 26TB of data. Even with a high-speed backbone, the egress costs are eye-watering, and the bandwidth saturation practically guarantees a slow rollout. This isn't just a hypothetical problem; it's a physical limitation of centralized distribution. When every node competes for the same bandwidth pipe to the registry, you create a bottleneck that even the beefiest cloud provider services can't always solve without significant throttling.
The Thundering Herd Problem
When thousands of containers attempt to pull the same large image simultaneously, they create a 'thundering herd' effect. This leads to registry performance degradation where the metadata service and the storage backend become overwhelmed. Most teams try to fix this by adding more registry mirrors or caching layers, but you're still essentially building a bigger funnel. Dragonfly P2P image distribution solves this by flattening the hierarchy entirely.
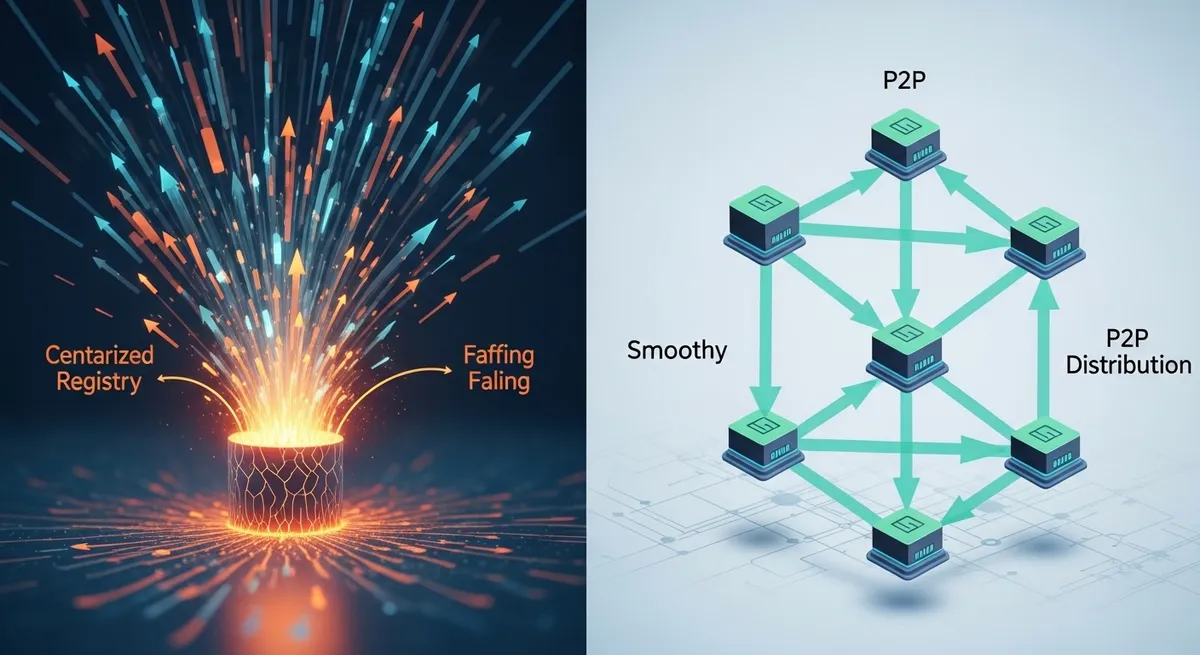
How Dragonfly Flattens the Distribution Curve
Dragonfly doesn't replace your registry; it intercepts the traffic. Using a local proxy called dfdaemon, it tricks the container engine (be it containerd or Docker) into thinking it's talking to the registry, while it's actually participating in a sophisticated peer-to-peer mesh. According to technical benchmarks from the CNCF, this strategy can reduce back-to-origin traffic by over 99.5%.
The Seed Peer Architecture
The magic happens through a decoupled architecture consisting of three main components:
- Manager: The brain that handles configurations, keep-alives, and visualizes the cluster status.
- Scheduler: The traffic controller that decides which peers should talk to which other peers to optimize for the shortest path and lowest latency.
- Seed Peers: These act as the 'super nodes' that pull the initial data from the origin registry.
Once a Seed Peer has the first 'piece' of an image, it serves it to a group of worker nodes. Those nodes, in turn, serve that piece to their neighbors. Instead of 200 nodes hitting ECR for 130GB each, only the Seed Peer hits the registry once. The other 199 nodes share the data internally at VPC speeds. The result? That 26TB of registry egress drops to just 130GB.
RDMA and the AI Revolution
For the SREs and Platform Engineers supporting GPU clusters, the stakes are even higher. AI models are getting larger, and training/inference restarts can't afford to wait 20 minutes for a container pull. Dragonfly v2.0 supports Remote Direct Memory Access (RDMA), allowing for ultra-low latency data transfer between nodes by bypassing the CPU and OS networking stack. This makes distributed container orchestration for AI feel instantaneous, even when moving massive weights across thousands of GPUs.
The Trade-offs: It's Not All Free Lunch
Before you go 'all-in,' we need to talk about the 'gotchas.' First, there's the name. In the SRE community, 'Dragonfly' is often confused with the multi-threaded Redis alternative or even old Google projects. Make sure you're looking at the CNCF project. More importantly, Dragonfly adds operational overhead. You are now managing a Manager, a Scheduler, and daemonsets across your cluster. This is an architectural shift that requires robust monitoring.
Furthermore, if misconfigured, a P2P mesh can saturate your internal VPC bandwidth. While you're saving money on registry egress, you're increasing intra-node traffic. You must ensure your network policies and bandwidth limits are tuned so that image distribution doesn't starve your actual application traffic.
Integrating with Nydus for 'Lazy Loading'
If you really want to achieve peak performance, Dragonfly works seamlessly with Nydus, an image service that enables lazy loading. Instead of waiting for the entire 10GB image to download before starting the container, Nydus allows the container to start as soon as the essential metadata is present. It then pulls the required data chunks on-demand via the Dragonfly P2P network. This combination can reduce container start times from minutes to mere seconds, providing a critical edge for reactive scaling.
Final Thoughts
Relying on a centralized registry for massive, high-concurrency deployments is a recipe for disaster. As we move into an era of massive AI models and hyperscale Kubernetes clusters, the Dragonfly P2P image distribution model is no longer a 'nice-to-have'—it's a fundamental requirement for resilience. By offloading the heavy lifting from your registry to a peer-to-peer mesh, you eliminate the thundering herd and ensure your infrastructure scales as fast as your traffic. It's time to stop treating your registry like a magic bucket and start treating your nodes like the powerful distribution assets they are.
Ready to harden your distribution layer? Check out the Dragonfly documentation and start by benchmarking your current pull times during a simulated scale event. Your 3 AM self will thank you.

